· Noorle Team · 8 min read
Compute Engines for AI Agents: Why One Size Doesn't Fit All
When deploying AI agents that execute code, choosing the right compute engine becomes critical. Understanding the trade-offs reveals why successful AI agent platforms need multiple compute options working in tandem.
When deploying AI agents that execute code, manipulate data, or orchestrate workflows, choosing the right compute engine becomes critical. The landscape offers everything from microsecond-booting WebAssembly runtimes to bulletproof virtual machines, each optimizing for different priorities. Understanding these trade-offs reveals why successful AI agent platforms need multiple compute options working in tandem—and why we built Noorle with a three-tier compute architecture.
The Compute Engine Landscape
Containers: The Production Workhorse
Containers have become the de facto standard for production AI deployments, achieving near-native performance with minimal overhead. When images are pre-pulled and cached, containers can start in under 100 milliseconds, though Kubernetes orchestration and image pulls often push total deployment times to 1-3 seconds in practice.
Strengths:
- Near-native performance (within 0.12% of bare metal for many workloads)
- Mature ecosystem with Kubernetes orchestration
- Excellent GPU support via NVIDIA Container Toolkit
- High density—hundreds to thousands per host
- OCI standardization ensures portability
Weaknesses:
- Shared kernel creates security risks for untrusted code
- Recent vulnerabilities demonstrate ongoing escape risks
- Requires additional hardening layers (gVisor, Kata) for untrusted workloads
- Complex orchestration for large-scale deployments
For AI agents, containers excel at running trusted model servers and tool backends but require additional security layers when executing dynamically generated code.
MicroVMs: Security Meets Speed
Firecracker microVMs revolutionized serverless computing by combining VM-level isolation with container-like agility. Fresh microVM launches take approximately 125-150ms, with snapshot restore achieving millisecond-class resumption. The VMM adds just 5MB overhead (excluding guest memory), enabling AWS to create up to 150 microVMs per second per host.
Strengths:
- Hardware-level isolation with minimal overhead
- Defense-in-depth security (VM isolation + process jails + seccomp)
- High density for VM-based isolation
- Ideal for multi-tenant environments
- Immutable, ephemeral by design
Weaknesses:
- No production GPU support (community discussions ongoing for 2025+)
- Limited to CPU-only workloads currently
- Higher complexity than containers
- Slightly higher latency than native containers
MicroVMs represent the sweet spot for executing untrusted agent code safely at scale, though GPU limitations restrict their use for inference tasks.
WebAssembly: The Edge Pioneer
WebAssembly module instantiation happens in microseconds (approximately 5μs in modern runtimes), with platforms like Cloudflare Workers achieving single-digit millisecond cold starts. This enables thousands of instances per host with minimal memory overhead.
Strengths:
- Near-instantaneous startup for module instantiation
- High density (thousands+ instances per host)
- Portable across browsers, servers, and edge locations
- Language agnostic with growing ecosystem
- Strong sandboxing for untrusted code
Weaknesses:
- Performance varies widely by workload (often slower than native, but gap narrowing with SIMD)
- GPU support remains experimental (WebGPU/WASI-GFX emerging but not production-ready)
- Limited POSIX compatibility
- Restricted system calls limit complex I/O operations
WebAssembly excels for lightweight agent tools and edge deployment, with emerging GPU capabilities via WebGPU showing promise for future AI workloads.
Traditional VMs: Maximum Isolation, Measured Overhead
Modern virtual machines have dramatically reduced their performance penalties. VMware vSphere 8 with vGPU achieves 95-104% of bare metal performance in MLPerf Inference benchmarks. Cold starts range from seconds to tens of seconds depending on image optimization and initialization complexity, with tuned cloud images often booting in under 10 seconds.
Strengths:
- Complete OS isolation with decades of hardening
- Full GPU passthrough with minimal overhead (workload-dependent, typically 2-5%)
- Supports any operating system or software stack
- Meets strictest compliance requirements
- Mature tooling and management
Weaknesses:
- Higher startup latency than containers or microVMs
- Hypervisor overhead of tens to hundreds of MB (plus allocated guest memory)
- Lower density than container-based solutions
- Higher operational complexity
- Overkill for short-lived agent tasks
VMs remain ideal for persistent services, complex agent environments, and workloads requiring full GPU acceleration with strong isolation.
Serverless Platforms: Scale Without Infrastructure
Serverless functions abstract infrastructure entirely, with cold start characteristics varying dramatically by platform. Cloudflare Workers achieve near-zero cold starts using V8 isolates, while AWS Lambda’s cold starts vary by runtime and package size (often 100-500ms with optimizations like SnapStart).
Strengths:
- Infinite scaling with zero management
- Pay only for actual execution time
- No idle costs with scale-to-zero
- Handles traffic spikes automatically
- Built-in high availability
Weaknesses:
- Cold start penalties vary widely by platform and runtime
- Execution time limits (platform-specific)
- Limited local storage and state management
- Vendor lock-in concerns
- Can become expensive for high-frequency operations
Serverless can be cost-effective for variable workloads, but the per-execution pricing model becomes prohibitive when agents perform hundreds or thousands of operations per session.
The Spectrum of Agent Workloads
Rather than a simple binary, AI agent workloads exist on a spectrum:
Lightweight Operations (60-70% of executions)
- Data validation and transformation
- API response parsing
- Simple calculations
- Quick file manipulations
- Testing hypotheses
- Exploratory analysis
These happen hundreds of times per session and need millisecond response times with minimal overhead.
Medium-Complexity Tasks (20-30% of executions)
- Data processing pipelines
- API orchestration
- Lightweight ML inference
- Multi-step workflows with transient state
- Prototyping solutions
These benefit from more resources but don’t require full system access.
Heavy Operations (10-20% of executions)
- Software compilation and installation
- Docker container management
- Persistent service deployment
- GPU-accelerated inference
- Complex system configuration
- Production deployments
These demand full OS capabilities and often GPU access.
The Fundamental Challenge
This spectrum reveals why no single compute engine suffices:
- Secure isolation increases costs: MicroVMs and full VMs provide strong boundaries but add latency and resource consumption that compounds over thousands of operations
- Lightweight runtimes limit capabilities: WebAssembly and isolates boot instantly but lack GPU support and full system access
- Containers require hardening: Default configurations share kernels, requiring additional layers that add complexity
- Serverless becomes expensive at scale: Per-execution pricing that seems reasonable for occasional use becomes prohibitive when agents execute hundreds of operations
Most critically, the economics don’t align with agent behavior. When an agent might test dozens of approaches, validate hundreds of data points, or explore multiple solution paths before finding the right one, even small per-operation costs multiply rapidly.
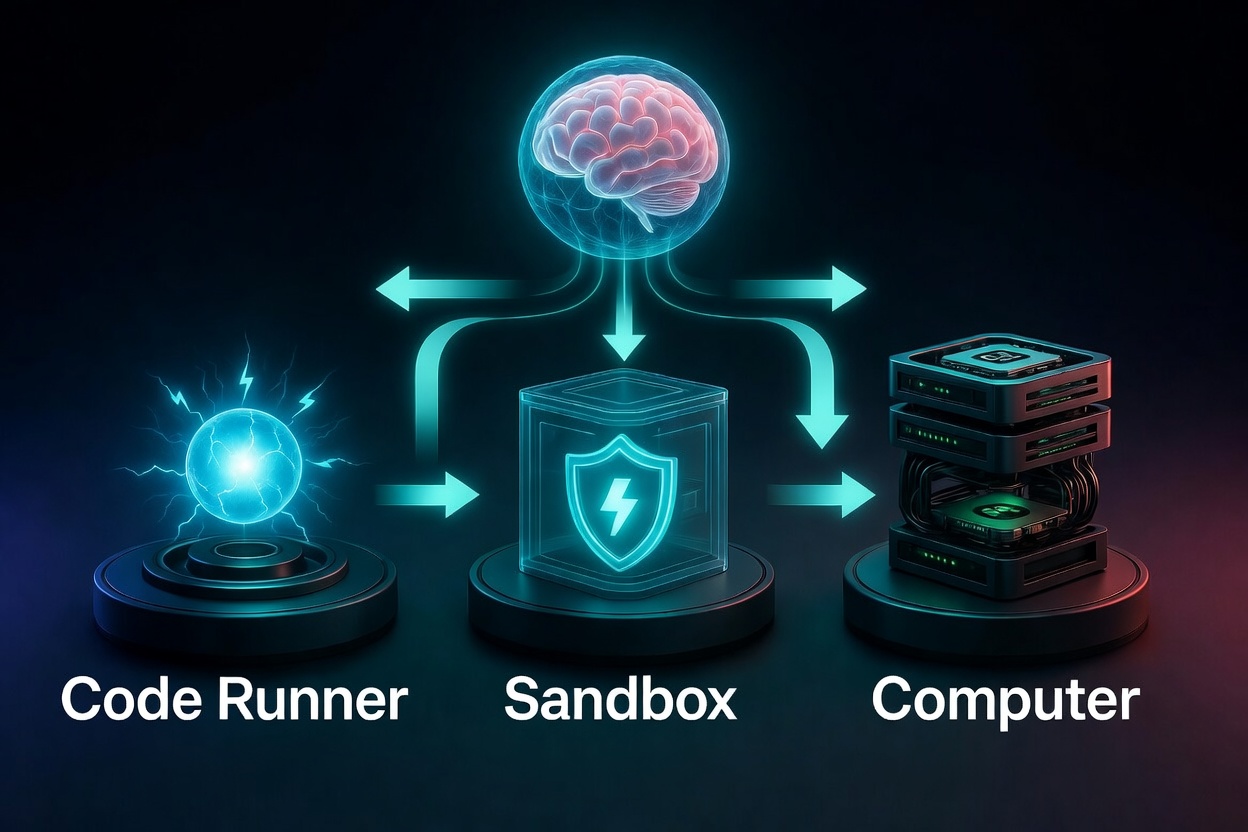
Why Noorle Built a Three-Tier Compute Architecture
This reality drove our architectural decision: agents need near-free exploratory compute, session-scoped environments for real work, AND persistent machines for long-running operations.
Tier 1 — Code Runner: Near-Zero Cost Exploration
Noorle’s Code Runner provides lightweight, WASM-sandboxed execution optimized for the thousands of small operations agents perform:
- Instant startup for Python and JavaScript execution
- WebAssembly sandboxing with memory limits and CPU fuel budgets
- Minimal overhead enabling rapid iteration
- Near-zero cost per execution—agents can run thousands of code snippets without impacting your budget
This isn’t just about cost savings—it’s about enabling a different mode of operation. When execution is virtually free, agents can:
- Test multiple hypotheses in parallel
- Validate every data point thoroughly
- Explore alternative approaches without concern for budget
- Iterate rapidly toward optimal solutions
Tier 2 — Sandbox: Session-Scoped Linux Containers
When agents need more than standard library Python or JavaScript, Sandbox provides full Linux containers with workspace volumes mounted:
- Full Linux environment with apt-get, pip, npm — install any package
- Workspace integration with input/output directories mounted as native volumes
- Configurable sizes from XS to XL to match workload requirements
- Session-scoped — containers persist across tool calls within a session, then clean up
- Configurable timeouts up to 30 minutes per execution
Sandbox is the workhorse for data processing, web scraping, and any task that needs real system access without the cost of a persistent machine.
Tier 3 — Computer: Persistent Machines with Browser
For agents that need a dedicated, always-on environment, Computer provides persistent VPS-based Linux machines:
- Persistent across sessions — the machine stays running between conversations
- Shell access with run, read, and write tools for full system control
- Built-in browser with navigation, screenshots, PDF generation, and tab management
- Lifecycle management with status checks and reboot capability
- Agent-only — exclusively available to autonomous agents, not MCP gateway clients
Computer is the right choice for agents that maintain long-running services, need browser automation for web interactions, or require a dedicated development environment that survives across sessions.
Seamless Promotion Between Tiers
The magic happens in the transition. Agents naturally start with lightweight exploration in the Code Runner—testing ideas, validating approaches, prototyping solutions. When they need packages or system access, they promote to Sandbox. When they need persistence or browser automation, they use Computer.
This mirrors how human developers work:
- Sketch in a REPL (Code Runner): Quick tests, data exploration, hypothesis validation
- Build and process (Sandbox): Install packages, run pipelines, process data
- Deploy and automate (Computer): Persistent services, browser automation, long-running operations
The Economic Advantage
Consider a typical agent session:
- 500 data validation checks
- 200 API response transformations
- 100 exploratory calculations
- 50 data processing jobs
- 5 browser automation tasks
With serverless or VM-only approaches, those 850 lightweight operations would accumulate significant costs. With Noorle’s three-tier model:
- 800 operations in Code Runner: Near-zero cost
- 50 processing jobs in Sandbox: Pay-per-second container rates
- 5 browser tasks on Computer: Persistent machine, always ready
- Total cost: Fraction of alternatives
This isn’t theoretical—it’s the difference between agents that can explore freely versus those constrained by per-operation economics.
Future-Proofing Through Flexibility
As the compute landscape evolves—WebAssembly gaining GPU support, Firecracker adding PCIe passthrough, new isolation technologies emerging—our three-tier architecture positions us to adopt innovations selectively:
- Enhance the Code Runner with new lightweight technologies
- Upgrade Sandbox with new container runtimes
- Expand Computer capabilities as hardware improves
- Maintain consistent APIs while improving underlying implementations
Operational Simplicity
Despite having three compute tiers, the complexity is hidden from users. Each tier is available as a built-in capability that agents use naturally based on what the task requires:
- Code Runner for quick calculations and data transforms
- Sandbox when packages, shell access, or workspace volumes are needed
- Computer when persistence, browsers, or long-running services are required
Agents choose the right tier based on the task at hand, and you only pay for what each tier costs.
Conclusion
The search for a universal compute engine for AI agents misses a fundamental point: different operations have vastly different requirements and economic profiles. By providing a near-free Code Runner for exploration, session-scoped Sandbox containers for real work, and persistent Computer machines for long-running operations, Noorle enables agents to operate the way developers actually work—iterating cheaply, processing efficiently, and deploying robustly.
This three-tier architecture isn’t just a technical optimization—it’s an economic enabler. When agents can explore without cost concerns, they become more effective at finding optimal solutions. When they can access full Linux environments on demand, they can process data at scale. And when they have persistent machines with browsers, they can automate the web and maintain long-running services.
The future of AI agent infrastructure isn’t about choosing the perfect compute engine. It’s about providing the right engine for each task, with economics that encourage exploration and capabilities that enable execution.


